Iceberg表的操作 - 环境准备
EMR Serverless环境设置
EMR Studio 是基于 Web 的 IDE,它可以使用 EMR Serverless 作为计算引擎
下载notebook: https://pingfan.s3.amazonaws.com/files/emr_iceberg_basics.ipynb
点击 studio1 Studio Access URL:

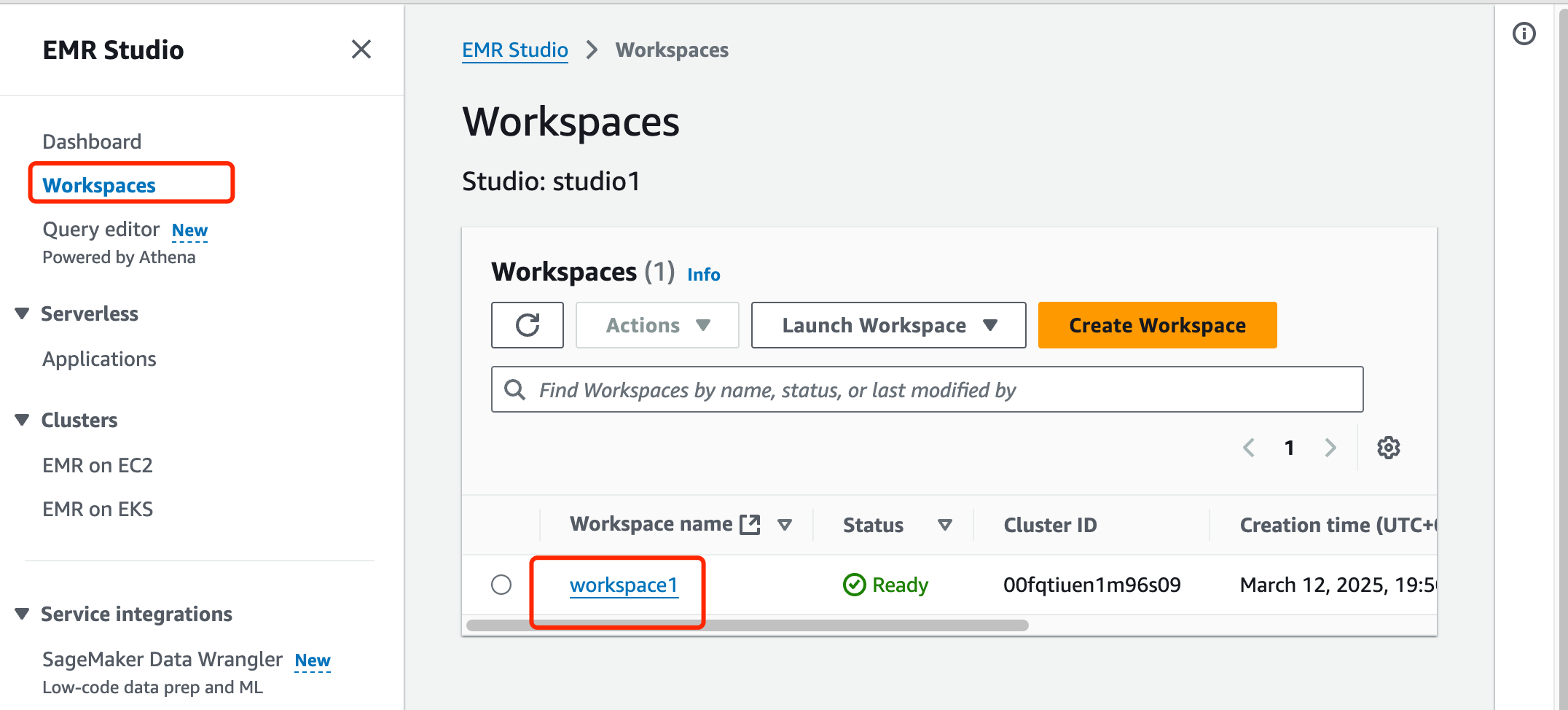
在 EMR Studio studio1 内,从左侧面板选择 Workspaces。我们应该看到一个名为 workspace1 的现有工作区。点击其名称打开它。
点击左侧导航窗格中的 EMR 集群图标,确认工作区已连接到 EMR Serverless 应用程序(Serverless application is attached to the Workspace)。
如果没有,请按照以下步骤操作:
- 将 Compute type 设置为
EMR Serverless application。 - 从 EMR Serverless application 下拉菜单中,选择
Serverless_Interactive_App_1。 - 对于 Interactive Runtime Role,指定
otfs-workshop-AmazonEMRStudio_RuntimeRole。 - 点击 Attach。

使用 Upload Files 按钮上传下载的notebook:

上传完成后,双击notebook打开它,确认右上角的 Kernel 设置为 Pyspark。

接下来就能运行notebook中的每一个cell了。
配置Notebook环境
下面创建了一个名为iceberg_catalog的新Spark Catalog,该Catalog与Glue Data Catalog兼容,并支持Iceberg表。spark.sql.catalog.<catalog_name>.warehouse属性用于设置在iceberg_catalog中创建的数据库和表的默认位置。
更新属性spark.sql.catalog.iceberg_catalog.warehouse并将**<your-account-id>**占位符替换为当前的账户ID。
%%configure -f
{
"numExecutors": 3,
"executorMemory": "14G",
"executorCores": 4,
"conf":{
"spark.sql.catalog.iceberg_catalog.warehouse":"s3://otfs-workshop-data-<your-account-id>/datasets/emr_iceberg/",
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"spark.sql.catalog.iceberg_catalog":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.iceberg_catalog.catalog-impl":"org.apache.iceberg.aws.glue.GlueCatalog",
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory",
"spark.dynamicAllocation.enabled": "false"
}
}
先定义了一些将在整个notebook中使用的变量。更新变量BUCKET_NAME并将**<your-account-id>**占位符替换为当前的账户ID。
#修改此变量
BUCKET_NAME = "otfs-workshop-data-<your-account-id>"
# python配置 - 请勿修改
SERVICE = 'emr'
TPC_DS_DATABASE = "tpcds"
TPC_DS_CUSTOMER_TABLE = "prepared_customer"
TPC_DS_SALES_TABLE = "prepared_web_sales"
ICEBERG_CATALOG="iceberg_catalog"
ICEBERG_DB = f"{SERVICE}_iceberg_db"
ICEBERG_CUSTOMER_TABLE = "customer_iceberg"
ICEBERG_SALES_TABLE = "web_sales_iceberg"
ICEBERG_CATALOG_PATH=f"datasets/{SERVICE}_iceberg"
ICEBERG_DATABASE_PATH=f"{ICEBERG_CATALOG_PATH}/{ICEBERG_DB}.db"
WAREHOUSE_PATH=f"s3://{BUCKET_NAME}/{ICEBERG_CATALOG_PATH}"
# sparkmagic SQL配置 - 请勿修改
spark.conf.set('ICEBERG_CATALOG', ICEBERG_CATALOG)
spark.conf.set('ICEBERG_DB', ICEBERG_DB)
spark.conf.set('ICEBERG_CUSTOMER_TABLE', ICEBERG_CUSTOMER_TABLE)
spark.conf.set('TPC_DS_DATABASE', TPC_DS_DATABASE)
spark.conf.set('TPC_DS_CUSTOMER_TABLE', TPC_DS_CUSTOMER_TABLE)

导入一些将在整个笔记本中使用的库。此外,我们设置一些实用函数,这些函数将在整个笔记本中用于显示S3中作为给定Iceberg表一部分的文件夹和文件。
S3 文件系统操作相关函数:
def list_files_recursively(bucket_name, prefix):
def print_files_tree(files_dict, indent=0):
-
这些函数用于递归列出 S3 存储桶中的文件和目录结构
-
以树形结构展示文件系统的层次关系
Iceberg 表文件查看功能:
def show_tables_files(table_name):
def show_data_files(table_name):
def show_tables_files_partition(partition, table_name):
-
展示 Iceberg 表的完整文件结构
-
只查看数据文件
-
查看特定分区的文件
元数据管理相关函数:
def get_current_metadata_pointer(table_name):
def show_current_metadata_pointer(table_name):
def show_current_metadata_file(table_name):
-
获取和显示当前表的元数据位置
-
通过 AWS Glue 获取表的元数据信息
-
读取和显示元数据文件内容
快照管理相关函数
def get_current_snapshot_manifest_list_file_name(table_name):
def get_current_snapshot_manifest_list(table_name):
def print_snapshot_files_summary(snapshot_id, table_name):
def print_snapshots_files_summary(table_name):
def print_current_snapshot_files_summary(table_name):
-
获取和显示快照的清单文件
-
展示快照中的数据文件状态(存在/添加/删除)
-
提供快照文件的详细摘要信息
import boto3
import json
from pyspark.sql.functions import to_timestamp
from pyspark.sql.types import TimestampType
from pyspark.sql.functions import col
from datetime import datetime, timedelta
s3_client = boto3.client('s3')
current_region = s3_client.meta.region_name
glue_client = boto3.client('glue', current_region)
def list_files_recursively(bucket_name, prefix):
paginator = s3_client.get_paginator('list_objects_v2')
operation_parameters = {'Bucket': bucket_name, 'Prefix': prefix}
files_dict = {}
for page in paginator.paginate(**operation_parameters):
if 'Contents' in page:
for obj in page['Contents']:
file_key = obj['Key']
if file_key.endswith('/'): # 这是一个目录
relative_key = file_key[len(prefix):] # 移除前缀
if relative_key: # 检查是否为空字符串
folders = relative_key.split('/')[:-1] # 移除最后一个空字符串元素
current_dict = files_dict
for folder in folders:
if folder not in current_dict:
current_dict[folder] = {}
current_dict = current_dict[folder]
else: # 这是一个文件
relative_key = file_key[len(prefix):] # 移除前缀
if '/' in relative_key: # 这是子目录中的文件
parent_folder, file_name = relative_key.rsplit('/', 1)
current_dict = files_dict
for folder in parent_folder.split('/'):
if folder:
if folder not in current_dict: # 检查键是否存在
current_dict[folder] = {}
current_dict = current_dict[folder]
current_dict[file_name] = obj['LastModified'].strftime("%Y-%m-%d %H:%M:%S")
else: # 这是根目录中的文件
current_dict = files_dict
if 'data' not in current_dict: # 检查键是否存在
current_dict['data'] = {}
current_dict = current_dict['data']
files_dict[relative_key] = obj['LastModified'].strftime("%Y-%m-%d %H:%M:%S")
return files_dict
def print_files_tree(files_dict, indent=0):
for key, value in files_dict.items():
if isinstance(value, dict): # 这是一个文件夹
print(" " * indent + "- " + key)
print_files_tree(value, indent + 1)
else: # 当遇到第一个文件时,按ModifiedTime对dict进行排序
sorted_files = (sorted(files_dict.items(), key=lambda item: item[1]))
for file_name, last_modified in sorted_files:
print(" " * indent + "--- " + file_name + " (" + last_modified + ")")
break
def show_tables_files(table_name):
ICEBERG_TABLE_PATH = f"{ICEBERG_DATABASE_PATH}/{table_name}"
print(f"表根位置:\n s3://{BUCKET_NAME}/{ICEBERG_TABLE_PATH}/ \n\n")
print("文件夹和文件:\n")
files_dict = list_files_recursively(BUCKET_NAME, ICEBERG_TABLE_PATH)
print_files_tree(files_dict)
def show_data_files(table_name):
ICEBERG_TABLE_PATH = f"{ICEBERG_DATABASE_PATH}/{table_name}"
prefix=f"{ICEBERG_TABLE_PATH}/data"
print("文件夹和文件:\n")
files_dict = list_files_recursively(BUCKET_NAME, prefix)
print_files_tree(files_dict)
def show_tables_files_partition(partition, table_name):
ICEBERG_TABLE_PATH = f"{ICEBERG_DATABASE_PATH}/{table_name}"
prefix=f"{ICEBERG_TABLE_PATH}/data/{partition}"
print(f"分区位置:\n s3://{BUCKET_NAME}/{prefix}/ \n\n")
print("文件夹和文件:\n")
files_dict = list_files_recursively(BUCKET_NAME, prefix)
print_files_tree(files_dict)
def get_current_metadata_pointer(table_name):
response = glue_client.get_table(
DatabaseName=ICEBERG_DB,
Name=table_name,
)
return response["Table"]["Parameters"]["metadata_location"]
def show_current_metadata_pointer(table_name):
current_metadata_pointer=get_current_metadata_pointer(table_name)
print(current_metadata_pointer)
from urllib.parse import urlparse
def get_s3_file_content(s3_path):
parsed_s3_path = urlparse(s3_path)
bucket_name = parsed_s3_path.netloc
object_key = parsed_s3_path.path.lstrip('/')
try:
response = s3_client.get_object(Bucket=bucket_name, Key=object_key)
file_content = response['Body'].read().decode('utf-8')
return file_content
except Exception as e:
print(f"错误: {e}")
return ""
def print_s3_file_content(s3_path):
file_content = get_s3_file_content(s3_path)
print(file_content)
def show_current_metadata_file(table_name):
current_metadata_pointer=get_current_metadata_pointer(table_name)
print_s3_file_content(current_metadata_pointer)
def get_current_snapshot_manifest_list_file_name(table_name):
current_metadata_pointer=get_current_metadata_pointer(table_name)
file_content = get_s3_file_content(current_metadata_pointer)
json_file = json.loads(file_content)
current_snapshot_id=json_file["current-snapshot-id"]
for snapshot in json_file["snapshots"]:
if snapshot["snapshot-id"] == current_snapshot_id:
snapshot_manifest_list_file = snapshot["manifest-list"]
return snapshot_manifest_list_file
def get_current_snapshot_manifest_list(table_name):
current_manifest_list=get_current_snapshot_manifest_list_file_name(table_name)
print(f"清单列表文件:\n{current_manifest_list}\n")
df_manifest_list = spark.read.format("avro").load(current_manifest_list)
return df_manifest_list
def remove_prefix(text, prefix):
if text.startswith(prefix):
return text[len(prefix):]
return text
def s3_path_without_prefix(s3_path, table_name):
ICEBERG_TABLE_PATH = f"{ICEBERG_DATABASE_PATH}/{table_name}"
prefix = f"s3://{BUCKET_NAME}/{ICEBERG_TABLE_PATH}/"
return remove_prefix(s3_path,prefix)
def print_snapshot_files_summary(snapshot_id, table_name):
print(f"\n====== 快照 {snapshot_id} ======\n")
print("数据文件状态: 0: 存在 - 1: 添加 - 2: 删除\n")
current_metadata_pointer=get_current_metadata_pointer(table_name)
file_content = get_s3_file_content(current_metadata_pointer)
json_file = json.loads(file_content)
snapshot_manifest_list_file=""
for snapshot in json_file["snapshots"]:
if snapshot["snapshot-id"] == snapshot_id:
snapshot_manifest_list_file = snapshot["manifest-list"]
print(f"[清单列表文件]: {s3_path_without_prefix(snapshot_manifest_list_file, table_name)}")
break
df_manifest_list = spark.read.format("avro").load(snapshot_manifest_list_file)
manifest_files=df_manifest_list.select("manifest_path", "added_snapshot_id").collect()
for mf in manifest_files:
manifest_file=mf["manifest_path"]
added_snapshot_id=mf["added_snapshot_id"]
print(f"\n--[清单文件]: {s3_path_without_prefix(manifest_file, table_name)} [由快照添加: {added_snapshot_id}]")
df_manifest_file = spark.read.format("avro").load(manifest_file)
data_files=df_manifest_file.select("data_file", "status").collect()
for df in data_files:
file_path=df["data_file"]["file_path"]
status=df["status"]
print(f" |-[数据文件]: {s3_path_without_prefix(file_path, table_name)} (状态: {status})")
def print_snapshots_files_summary(table_name):
current_metadata_pointer=get_current_metadata_pointer(table_name)
file_content = get_s3_file_content(current_metadata_pointer)
json_file = json.loads(file_content)
for snapshot in json_file["snapshots"]:
print_snapshot_files_summary(snapshot["snapshot-id"])
def print_current_snapshot_files_summary(table_name):
current_metadata_pointer=get_current_metadata_pointer(table_name)
file_content = get_s3_file_content(current_metadata_pointer)
json_file = json.loads(file_content)
print_snapshot_files_summary(json_file["current-snapshot-id"], table_name)
配置%%sql魔术命令以让每列显示更多字符,以便能够阅读表中的所有内容:
%%local
import pandas as pd
pd.set_option('display.max_colwidth', 10000)
Catalog
Spark中的默认Catalog为spark_catalog:
%%sql
SELECT current_catalog()

切换到iceberg_catalog,这是我们为Iceberg操作配置的Catalog:
%%sql
USE iceberg_catalog
验证current_catalog是iceberg_catalog:
%%sql
SELECT current_catalog()

可以使用具体的namespace访问另一个Catalog(非当前目录)中的数据库和表:<catalog_id>.<database_name>.<table_name>
%%sql
SHOW TABLES IN spark_catalog.${TPC_DS_DATABASE}

这个sql其实是查询的glue的database:

如果我们在cloudtrail里搜索GetTables事件,会找到对应的记录:
