title : “选项 1: Amazon Athena” weight : 51
在本实验中,我们将探索如何使用 Amazon Athena 查询 Iceberg 表。
请注意,Amazon Athena 为 Apache Iceberg 提供了内置支持,因此我们可以读取和写入 Iceberg 表,而无需添加任何额外的依赖项或配置。这适用于 Iceberg [v2 tables])(https://iceberg.apache.org/spec/#version-2-row-level-deletes)。
主要学习点:
- 使用 Amazon Athena 查询 Iceberg 表
- 使用 Iceberg 表创建视图
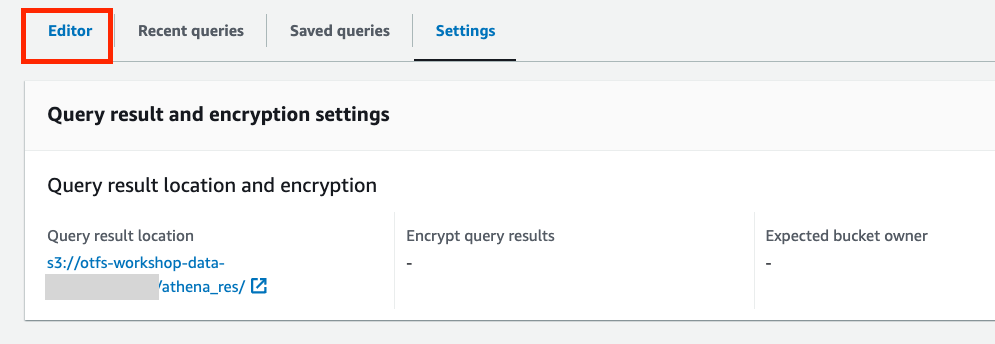
- 选择 Editor 进入查询编辑器页面。
查询 Iceberg 表
本节可用于查询在之前实验中创建的任何表。
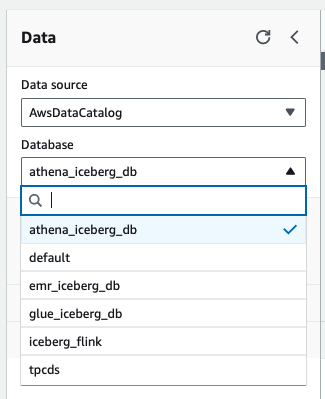
如果我们在 Glue 实验中创建了 `web_sales_iceberg` 和 `customer_iceberg` 表,请确保在运行查询之前在编辑器左侧窗格中选择 `glue_iceberg_db` 数据库,同样,如果我们在 EMR 实验中创建了表,则选择 `emr_iceberg_db`,或者如果我们在 Athena 实验中创建了表,则选择 `athena_iceberg_db`。
- 要查询 Iceberg 数据集,请使用如下标准 SELECT 语句。
SELECT ws_warehouse_sk, count(distinct(ws_order_number)) as num_orders
FROM web_sales_iceberg
WHERE ws_warehouse_sk in (5,6,10,11)
GROUP BY ws_warehouse_sk
注意:查询遵循 Apache Iceberg format v2 spec
。如果查询针对使用 merge-on-read 的表执行(例如,athena_iceberg_db 中的表),位置删除文件会与数据文件即时合并。
- 让我们检查表中存在的记录数量。
SELECT count(*)
FROM customer_iceberg
- 在 Athena 中使用 EXPLAIN 和 EXPLAIN ANALYZE
3.1 EXPLAIN 语句显示指定 SQL 语句的逻辑或分布式执行计划,或验证 SQL 语句。我们可以以文本格式或数据格式输出结果,以渲染为图形。
EXPLAIN SELECT count(*) FROM customer_iceberg LIMIT 10;
3.2 EXPLAIN ANALYZE 语句显示指定 SQL 语句的分布式执行计划以及 SQL 查询中每个操作的计算成本。我们可以以文本或 JSON 格式输出结果。
EXPLAIN ANALYZE
SELECT ws_warehouse_sk, count(distinct(ws_order_number)) as num_orders
FROM web_sales_iceberg
WHERE ws_warehouse_sk in (5,6,10,11)
GROUP BY ws_warehouse_sk
有关更多详细信息,请参阅 Athena EXPLAIN 语句结果 。
创建和查询带有 Iceberg 表的视图
- 要在 Iceberg 表上创建和查询 Athena 视图,请使用 CREATE VIEW 语句。将下面的查询复制到查询编辑器中,然后点击 Run。
CREATE VIEW total_orders_by_warehouse
AS
SELECT ws_warehouse_sk, count(distinct(ws_order_number)) as num_orders
FROM web_sales_iceberg
WHERE ws_warehouse_sk in (5,6,10,11)
GROUP BY ws_warehouse_sk
查询应该成功执行,我们将在查询结果中看到"Query successful.“消息。
- 要查询视图,请将下面的查询复制到查询编辑器中,然后点击 Run。
SELECT *
FROM total_orders_by_warehouse