Trino架构
Trino的核心架构包括协调器(Coordinator)和工作节点(Worker)
Trino采用了经典的主从分布式架构,由协调器(Coordinator)和工作节点(Worker)组成。这种架构设计使Trino能够高效地处理大规模数据查询,实现资源的合理分配和任 务的并行执行。
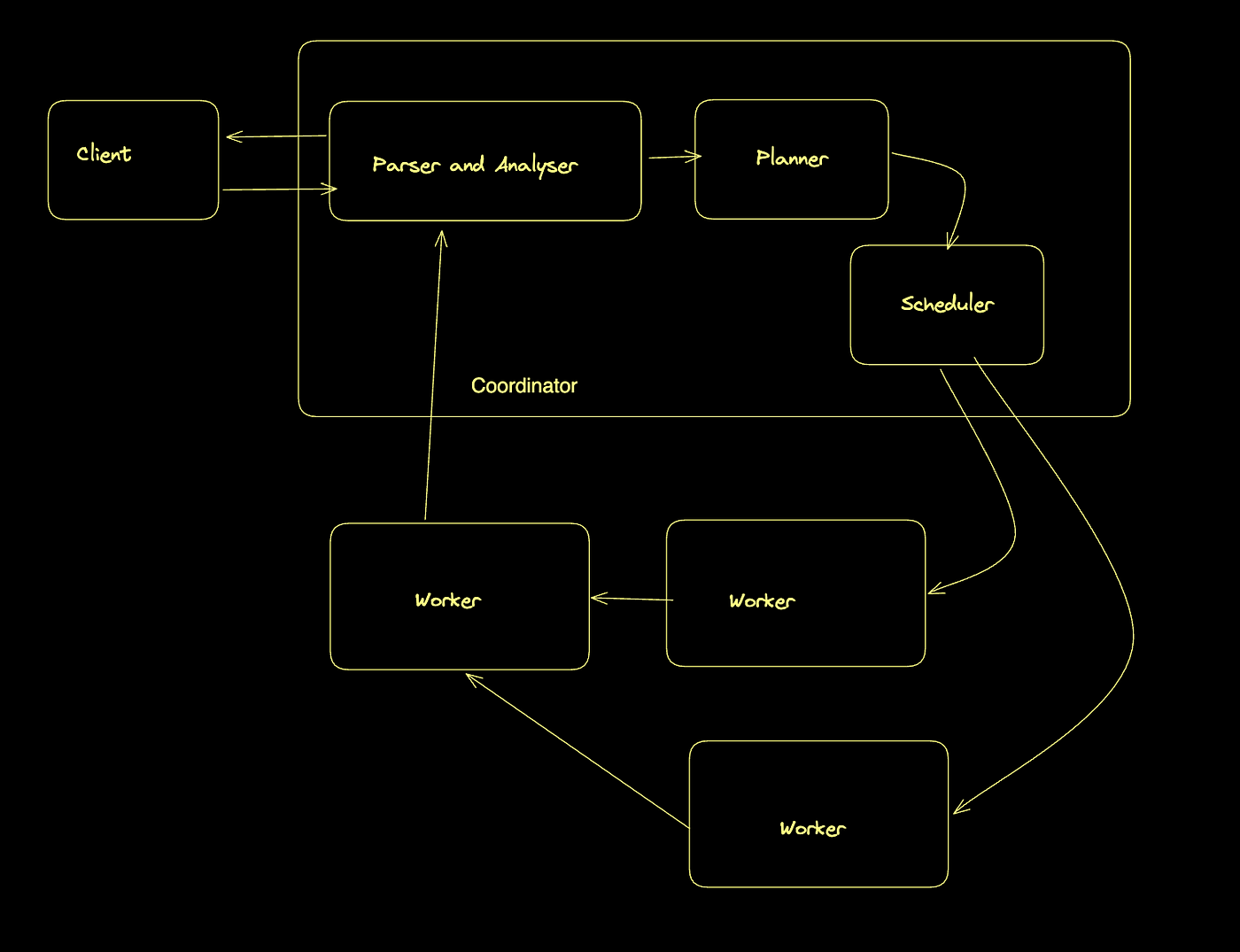
协调器(Coordinator)
协调器是Trino集群的大脑,负责管理整个查询生命周期。当用户提交SQL查询时,协调器首先接收这个请求,然后进行一系列复杂的处理步骤。
协调器首先解析SQL语句,将其转换为抽象语法树(AST),然后进行语义分析。在这个过程中,它会验证表名、列名是否存在,检查SQL语法是否正确,并确保用户有执行该 查询的权限。
接下来,协调器生成查询执行计划。这个计划决定了如何最高效地执行查询,包括表的访问顺序、连接算法的选择、以及谓词下推等优化策略。查询优化器在这个阶段发挥 关键作用,它会考虑数据分布、统计信息和系统资源等因素,生成最优的执行路径。
查询计划生成后,协调器将其分解为多个执行阶段(Stage),每个阶段又包含多个任务(Task)。协调器负责将这些任务分配给工作节点执行。在任务分配过程中,协调器会 考虑数据本地性、工作节点的负载情况和网络拓扑等因素,尽量减少数据传输和平衡系统负载。
在查询执行期间,协调器持续监控每个工作节点的执行情况,收集执行统计信息,并处理可能出现的错误。如果某个工作节点失败,协调器可以重新调度任务到其他节点, 确保查询能够继续执行。
最后,协调器从各个工作节点收集查询结果,进行必要的合并和处理,然后将最终结果返回给客户端。协调器还维护查询的元数据,包括执行时间、资源使用情况和错误信 息等,这些信息对于性能分析和问题排查非常有价值。
工作节点(Worker)
工作节点是Trino集群的计算引擎,负责执行协调器分配的查询任务。一个Trino集群通常包含多个工作节点,它们共同提供查询处理能力。
当工作节点接收到协调器分配的任务后,它会根据任务描述执行具体的数据处理操作。这些操作包括从数据源读取数据、执行过滤、投影、聚合、排序和连接等操作。工作 节点通过连接器(Connector)与各种数据源交互,这些连接器提供了统一的接口,使Trino能够访问不同类型的数据系统。
工作节点采用内存计算模型,尽可能将数据保存在内存中进行处理,以获得最佳性能。当内存不足时,工作节点会将中间结果溢写到磁盘,但这通常会导致性能下降。因此 ,合理配置工作节点的内存是优化Trino性能的关键因素之一。
工作节点之间可以直接通信,交换中间结果数据。这种设计使得数据可以在不经过协调器的情况下,直接在工作节点之间流动,减少了网络瓶颈和协调器的负担。例如,在 执行分布式连接操作时,工作节点会根据连接键对数据进行重分区,并将数据发送到相应的节点进行处理。
工作节点还实现了多种执行优化技术,如动态过滤、自适应执行和并行处理等。这些技术能够根据运行时情况调整执行策略,提高查询效率。
协调器与工作节点的交互
协调器和工作节点之间通过HTTP/HTTPS协议进行通信,交换控制信息和查询结果。这种基于标准协议的通信方式使得Trino集群可以部署在各种网络环境中,包括跨数据中 心或云环境。
在查询执行过程中,协调器和工作节点保持持续的通信。协调器向工作节点发送任务描述和控制命令,工作节点则向协调器报告执行状态和结果。这种实时通信机制使得协 调器能够动态调整查询执行计划,应对系统负载变化和节点故障。
值得注意的是,协调器本身也可以配置为工作节点,同时执行协调和计算任务。这种配置适用于小型集群或测试环境,但在生产环境中,通常建议将协调器和工作节点分开 ,以避免资源竞争和提高系统可靠性。
架构的可扩展性
Trino的协调器-工作节点架构具有良好的可扩展性。当查询负载增加时,可以通过添加更多的工作节点来提高系统的处理能力。协调器会自动发现新加入的工作节点,并将 其纳入资源池中。
对于非常大的集群,可以部署多个协调器来分担查询负载。在这种配置下,每个协调器独立处理一部分查询,但它们共享同一组工作节点。这种多协调器架构需要在前端部 署负载均衡器,将查询请求分发到不同的协调器。
Trino的架构还支持资源组管理,允许管理员为不同的用户组或查询类型分配不同的资源配额。这种细粒度的资源管理使得Trino能够在多租户环境中高效运行,满足不同用 户的需求。
通过这种协调器和工作节点的分工协作,Trino能够高效地处理复杂的分析查询,实现对海量数据的快速分析,为用户提供速接近实时的查询体验。
Trino的查询执行模型和内存管理
查询执行模型
Trino采用了一种独特的分布式查询执行模型,这种模型将复杂的SQL查询转换为高效的并行执行计划。当用户提交一个SQL查询后,Trino的执行过程可以分为几个关键阶段 。
首先,查询会经过解析和分析,转换为逻辑执行计划。这个逻辑计划代表了查询的抽象表示,包含了所有必要的操作,如表扫描、过滤、投影、聚合和连接等。在这个阶段 ,Trino会应用各种基于规则的优化,如谓词下推、列裁剪和常量折叠等,以简化执行计划。
接下来,逻辑计划会被转换为分布式物理执行计划。这个转换过程考虑了数据的分布情况、统计信息和可用资源等因素。物理计划由多个阶段(Stage)组成,每个阶段又包 含多个任务(Task)。阶段之间通过数据交换操作相连,形成一个有向无环图(DAG)。
Trino的执行模型采用了流水线处理方式,数据以页(Page)为单位在操作符之间流动。每个页包含多行数据,以列式格式存储,这种设计充分利用了现代CPU的缓存特性和向 量化处理能力。操作符按需处理数据,无需等待整个数据集加载完成,这大大减少了查询的延迟和内存占用。
在分布式执行过程中,Trino采用了多种数据交换模式。对于广播连接(Broadcast Join),小表的数据会被复制到所有参与连接的节点;对于分区连接(Partitioned Join) ,两个表的数据会根据连接键重新分区,确保相同键的数据位于同一节点。Trino会根据表的大小、统计信息和查询特点自动选择最合适的连接策略。
Trino还实现了动态过滤(Dynamic Filtering)技术,可以在运行时生成过滤条件,并将其应用到查询计划的早期阶段。例如,在星型模式查询中,Trino可以从维度表中提 取过滤条件,并将其推送到事实表的扫描阶段,大幅减少需要处理的数据量。
查询执行过程中,协调器持续监控各个任务的执行状态,并根据需要调整执行策略。如果某个任务失败,Trino会尝试重新执行该任务。如果失败次数超过阈值,整个查询 会被标记为失败。这种容错机制使得Trino能够在节点故障的情况下继续执行查询。
内存管理
Trino的内存管理是其高性能的关键因素之一。与传统的基于磁盘的数据处理系统不同,Trino尽可能将数据保留在内存中处理,以获得最佳性能。然而,内存是有限的资源 ,需要精心管理,特别是在处理大规模数据集时。
Trino采用了分层的内存管理架构。在集群层面,管理员可以配置总内存池大小,控制Trino可以使用的最大内存量。在查询层面,每个查询会被分配一定的内存配额,这个 配额可以根据查询的复杂度和优先级动态调整。在任务层面,内存会被进一步分配给各个操作符,如连接、聚合和排序等。
为了有效利用内存,Trino实现了多种内存优化技术。例如,列式存储格式减少了内存占用,因为同类型的数据存储在一起,可以更有效地压缩;懒加载策略确保只有实际 需要的数据才会被加载到内存中;内存池化技术减少了内存分配和回收的开销。
当查询的内存需求超过配额时,Trino会采取不同的策略。对于某些操作,如排序和聚合,Trino可以将中间结果溢写到磁盘,然后在需要时重新加载。这种溢写机制允许 Trino处理超出内存容量的大型数据集,虽然会导致性能下降。对于其他无法溢写的操作,如某些类型的连接,如果内存不足,查询可能会失败。
Trino还实现了内存压力检测机制。当系统内存压力增大时,Trino会主动释放不必要的内存缓存,或者拒绝新的查询请求,以保护系统稳定性。这种自适应的内存管理策略 使得Trino能够在各种负载条件下高效运行。
在多租户环境中,内存管理变得更加复杂。Trino通过资源组(Resource Group)机制,允许管理员为不同的用户组或查询类型分配不同的内存配额。这种细粒度的资源控制 确保了关键查询能够获得足够的资源,同时防止单个查询消耗过多资源影响整个系统。
Trino的内存管理还考虑了数据局部性原则。在分配任务时,协调器会尽量将任务分配给存储相关数据的节点,减少网络传输和内存消耗。对于需要在节点间交换的数据, Trino使用高效的二进制格式和压缩算法,进一步降低内存和网络带宽需求。
值得注意的是,Trino的内存管理是动态的,会根据查询特点和系统负载自动调整。例如,在执行连接操作时,Trino会根据表的大小和可用内存动态选择连接算法;在处理 聚合操作时,Trino会根据唯一键的数量和分布情况选择合适的聚合策略。
通过这种精细的查询执行模型和内存管理,Trino能够在有限的资源条件下高效处理复杂的分析查询,为用户提供接近实时的查询体验,同时保持系统的稳定性和可靠性。 管理员可以通过调整各种配置参数,如内存池大小、查询内存限制和溢写阈值等,进一步优化Trino的性能和资源利用率,适应不同的工作负载和硬件环境。