查询S3
通过Trino的强大功能,我们可以直接查询S3中的各种格式数据,包括Parquet、ORC、JSON、CSV等,无需将数据加载到传统数据库中。
准备S3数据
创建示例数据
让我们创建一些示例数据并上传到S3:
# 创建临时目录
mkdir -p ~/s3-data-demo/sales
# 创建CSV示例数据
cat > ~/s3-data-demo/sales/transactions.csv << EOF
transaction_id,customer_id,product_id,transaction_date,amount
1001,101,501,2023-01-15,125.99
1002,102,502,2023-01-16,89.50
1003,101,503,2023-01-18,45.75
1004,103,501,2023-01-20,125.99
1005,104,504,2023-01-22,199.99
1006,102,505,2023-01-25,65.25
1007,105,502,2023-01-28,89.50
1008,101,504,2023-02-01,199.99
1009,103,505,2023-02-05,65.25
1010,104,501,2023-02-10,125.99
EOF
# 创建JSON示例数据
cat > ~/s3-data-demo/sales/customers.json << EOF
{"customer_id": 101, "name": "John Doe", "email": "john.doe@example.com", "registration_date": "2022-12-01"}
{"customer_id": 102, "name": "Jane Smith", "email": "jane.smith@example.com", "registration_date": "2022-12-05"}
{"customer_id": 103, "name": "Robert Johnson", "email": "robert.j@example.com", "registration_date": "2022-12-10"}
{"customer_id": 104, "name": "Emily Davis", "email": "emily.d@example.com", "registration_date": "2022-12-15"}
{"customer_id": 105, "name": "Michael Brown", "email": "michael.b@example.com", "registration_date": "2022-12-20"}
EOF
上传数据到S3
将示例数据上传到您的S3存储桶:
# 替换为您的S3存储桶名称
S3_BUCKET="your-s3-bucket-name"
# 创建目标目录
aws s3 mb s3://$S3_BUCKET/trino-demo/
# 上传数据
aws s3 cp ~/s3-data-demo/sales/ s3://$S3_BUCKET/trino-demo/sales/ --recursive
在Hive Metastore中创建表
现在,我们需要在Hive Metastore中创建表定义,以便Trino可以查询S3数据:
# 启动Hive CLI
hive
在Hive中执行以下命令:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS s3_demo;
-- 使用数据库
USE s3_demo;
-- 创建指向S3 CSV文件的表
CREATE EXTERNAL TABLE transactions (
transaction_id INT,
customer_id INT,
product_id INT,
transaction_date DATE,
amount DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://your-s3-bucket-name/trino-demo/sales/'
TBLPROPERTIES ('skip.header.line.count'='1');
-- 创建指向S3 JSON文件的表
CREATE EXTERNAL TABLE customers (
customer_id INT,
name STRING,
email STRING,
registration_date DATE
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE
LOCATION 's3://your-s3-bucket-name/trino-demo/sales/';
-- 退出Hive
exit;
请确保将上述命令中的 your-s3-bucket-name 替换为您实际的S3存储桶名称。
使用Trino查询S3数据
现在,我们可以使用Trino查询存储在S3中的数据:
# 启动Trino CLI
trino-cli --server localhost:8889
在Trino中执行查询:
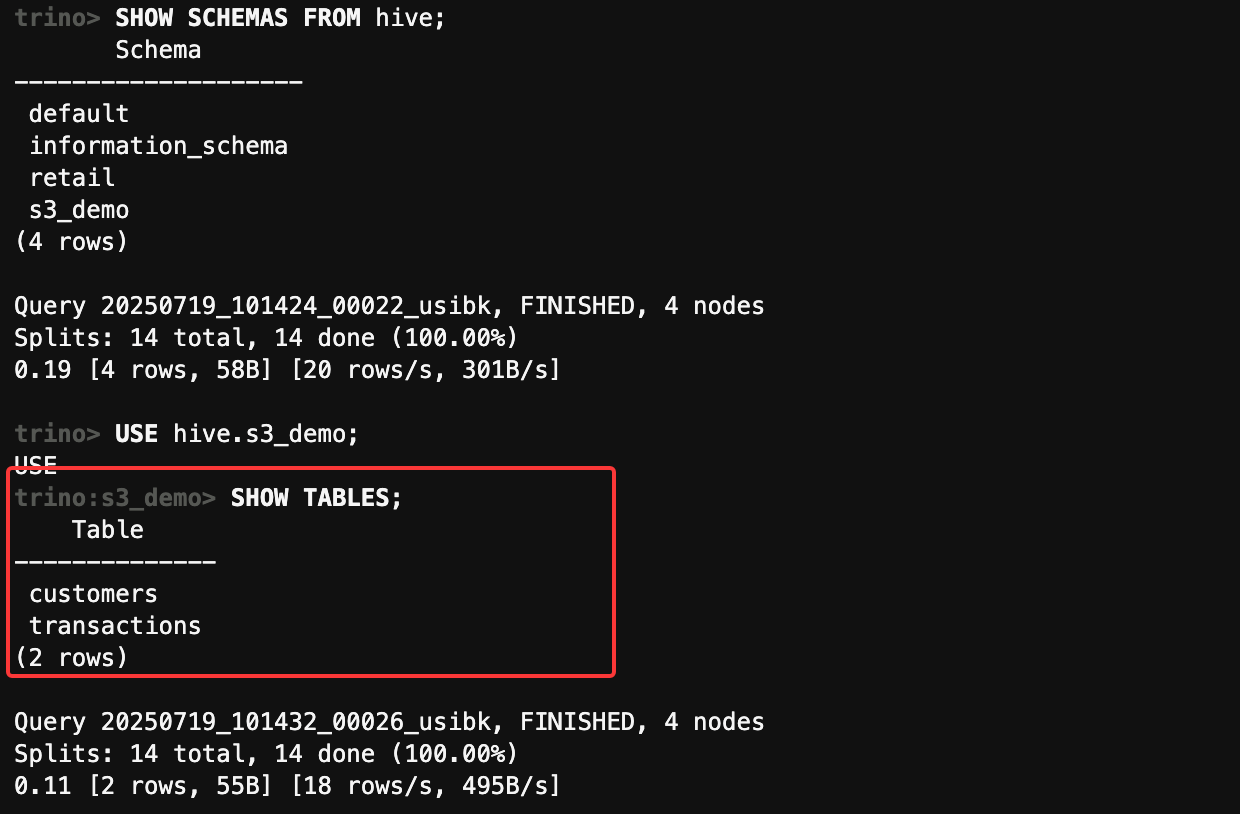
-- 列出所有目录
SHOW CATALOGS;
-- 列出Hive中的所有schema
SHOW SCHEMAS FROM hive;
-- 使用s3_demo schema
USE hive.s3_demo;
-- 列出所有表
SHOW TABLES;
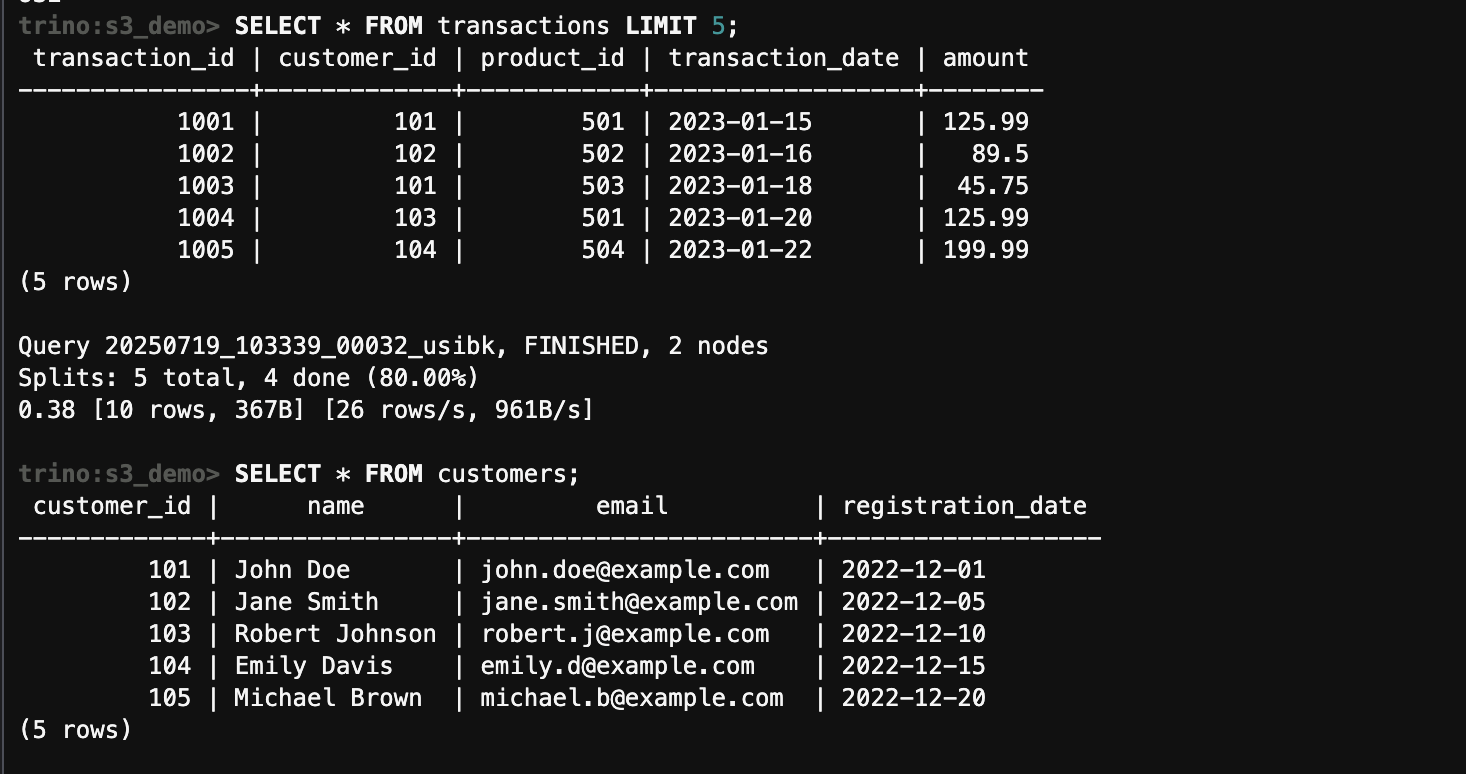
-- 查询CSV数据
SELECT * FROM transactions LIMIT 5;
-- 查询JSON数据
SELECT * FROM customers;
-- 退出Trino CLI
exit;
使用Trino创建表并写入S3
Trino不仅可以读取S3数据,还可以创建表并将数据写入S3:
-- 使用s3_demo schema
USE hive.s3_demo;
-- 创建新表并指定S3位置
CREATE TABLE sales_summary (
category VARCHAR,
year INTEGER,
month INTEGER,
total_sales DOUBLE
)
WITH (
format = 'PARQUET',
external_location = 's3://your-s3-bucket-name/trino-demo/sales/summary/'
);
-- 插入数据到新表
INSERT INTO sales_summary (category, year, month, total_sales) VALUES
('电子产品', 2023, 1, 125000.50),
('电子产品', 2023, 2, 135750.75),
('电子产品', 2023, 3, 142500.25),
('服装', 2023, 1, 85000.00),
('服装', 2023, 2, 92500.50),
('服装', 2023, 3, 88750.25),
('家居用品', 2023, 1, 67500.75),
('家居用品', 2023, 2, 72000.00),
('家居用品', 2023, 3, 78500.50),
('食品', 2023, 1, 45000.25),
('食品', 2023, 2, 47500.75),
('食品', 2023, 3, 49250.00);
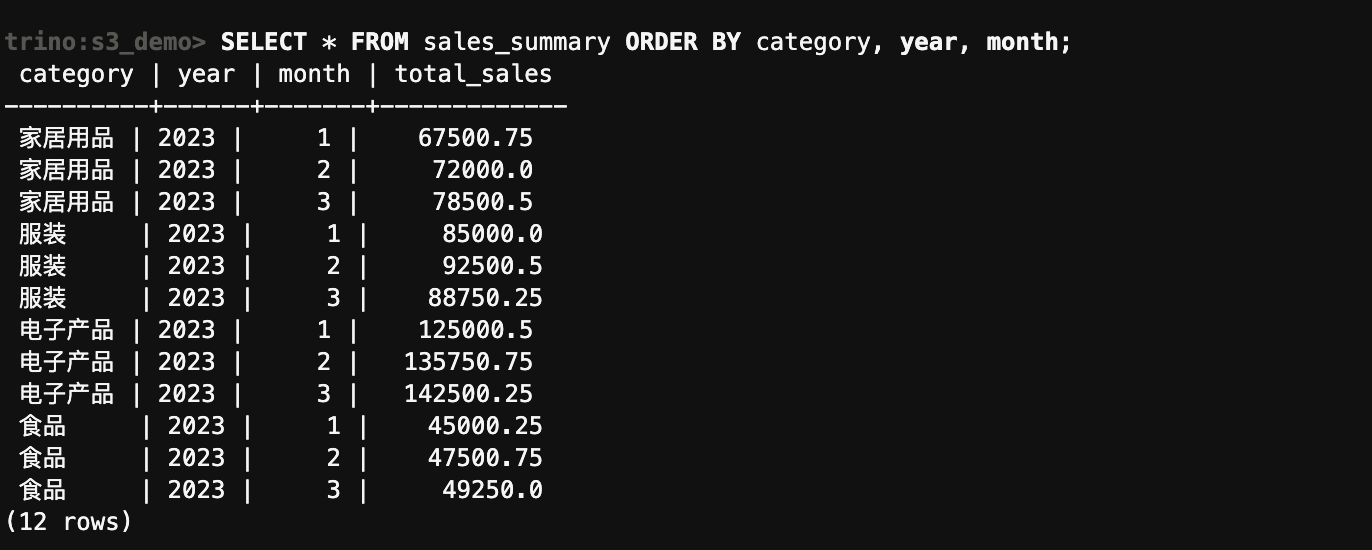
-- 查询新创建的表
SELECT * FROM sales_summary ORDER BY category, year, month;
-- 退出Trino CLI
exit;
查看s3文件:
aws s3 ls s3://xxxx/trino-demo/sales/summary/
2025-07-19 20:16:00 942 20250719_121558_00052_usibk_e915d985-fab9-4d39-8973-8d2d5f6d9e78
优化S3查询性能
- 使用列式存储格式:
Parquet和ORC等列式存储格式可以显著提高查询性能:
-- 创建使用Parquet格式的表
CREATE TABLE transactions_parquet
WITH (
format = 'PARQUET',
external_location = 's3://your-s3-bucket-name/trino-demo/sales/transactions_parquet/'
)
AS SELECT * FROM transactions;
- 使用分区
分区可以减少查询时需要扫描的数据量:
-- 创建分区表
CREATE TABLE transactions_partitioned (
transaction_id INT,
customer_id INT,
product_id INT,
transaction_date DATE,
amount DOUBLE
)
WITH (
format = 'PARQUET',
partitioned_by = ARRAY['EXTRACT(YEAR FROM transaction_date)', 'EXTRACT(MONTH FROM transaction_date)'],
external_location = 's3://your-s3-bucket-name/trino-demo/sales/transactions_partitioned/'
);
-- 插入数据到分区表
INSERT INTO transactions_partitioned
SELECT
transaction_id,
customer_id,
product_id,
transaction_date,
amount,
EXTRACT(YEAR FROM transaction_date) AS year,
EXTRACT(MONTH FROM transaction_date) AS month
FROM
transactions;
- 配置S3优化参数
在/etc/trino/conf/catalog/hive.properties中添加以下配置:
hive.s3.max-connections=500
hive.s3.multipart.min-file-size=128MB
hive.s3.multipart.min-part-size=64MB
hive.s3.max-client-retries=50
hive.s3.max-error-retries=20
hive.s3.socket-timeout=5m